SGLang 在 NVIDIA Spark GB10 的智能體應用
Table Of Contents
SGLang 在 NVIDIA Spark GB10 的智能體應用
Spark GB10 在香港市場的現況
據報導,PGX Spark 在本港銷情不俗,聯想、戴爾、HP 都有推出不同版本。華碩率先推出現貨 Ascent GX10 AI Workstation,坊間售價約港幣三萬元以下。代理商借出 Ascent GX10 供技術測試,讓我們可以率先評估 Spark GB10 Grace Blackwell 平台的安裝和性能表現。
2026:Agent 應用元年
2026 年被視為 Agent 之年。如果想利用 Spark GB10 Grace Blackwell 作為運行 Agent 平台,就必須掌握最佳實踐,並選擇適合的 LLM 和推理框架。
NVIDIA Spark GB10 技術規格
自從 NVIDIA 推出 PGX Spark,創辦人黃仁勳親自將新款 AI 超級電腦 DGX Spark 交付給 [埃隆·馬斯克] (Ticker: MSFT, Exchange: NASDAQ)。這部基於 NVIDIA GB10 Grace Blackwell 架構的系統,整合了 GPU、CPU、CUDA 等 NVIDIA AI 技術,運行基於 Ubuntu 的 PGX OS,具備 128 GB 的 LPDDR5x 統一系統記憶體。
如果需要更多算力,可以利用機背的 ConnectX-7 網絡接口,通過 NVIDIA 的 Mellanox 技術,使用 NCCL 接口合併兩部電腦的 GPU,實現分佈式運算。

推理框架的選擇:vLLM vs SGLang
推理框架方面,PGX Spark 可支援 Ollama,但 Ollama 不適合生產級環境,也不能支援多 Agent 和極長的上下文窗口。它的優勢在於可以安裝多個大模型進行測試。如果利用 PGX Spark 進行推理工作,主要選擇是 vLLM 或 SGLang。
vLLM 的特點
vLLM 是 NVIDIA 預裝的 LLM 推理框架。由於 vLLM 對 CUDA、編譯器、系統庫要求嚴格,一般會安裝在 NVIDIA 容器中運行。它可以通過極底層與 CUDA 對話,直接利用 GPU 進行並行處理,充分利用 SM 核心以獲得更高效率。vLLM 針對 NEON 指令集、GPU 進行了優化。
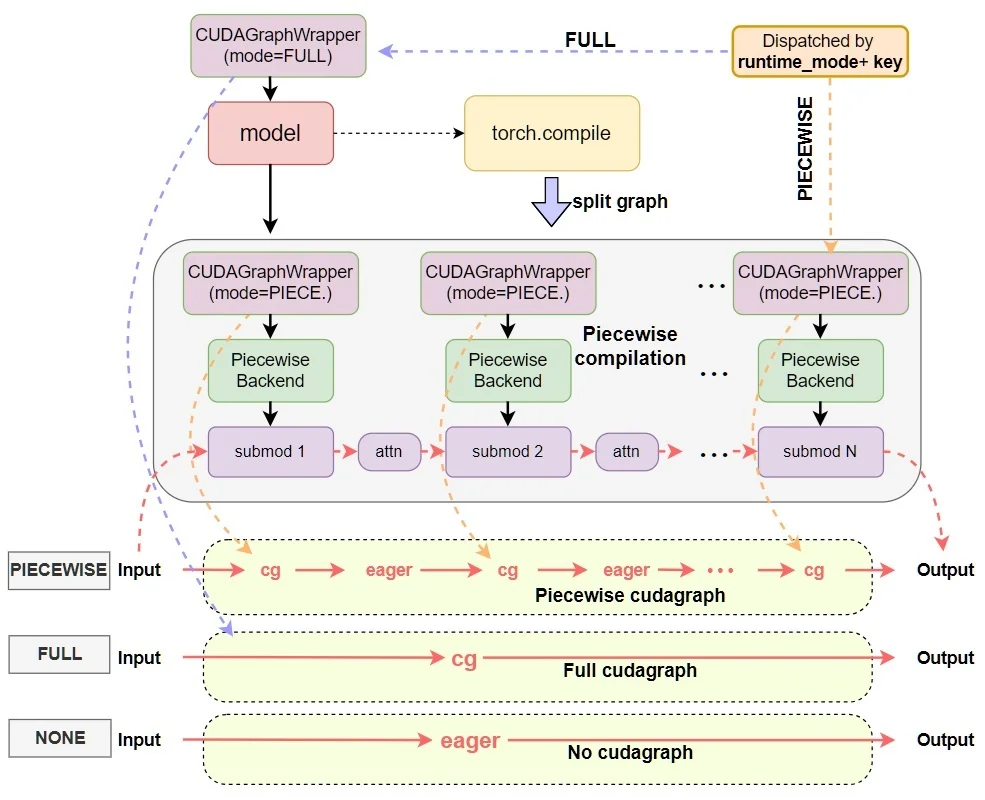
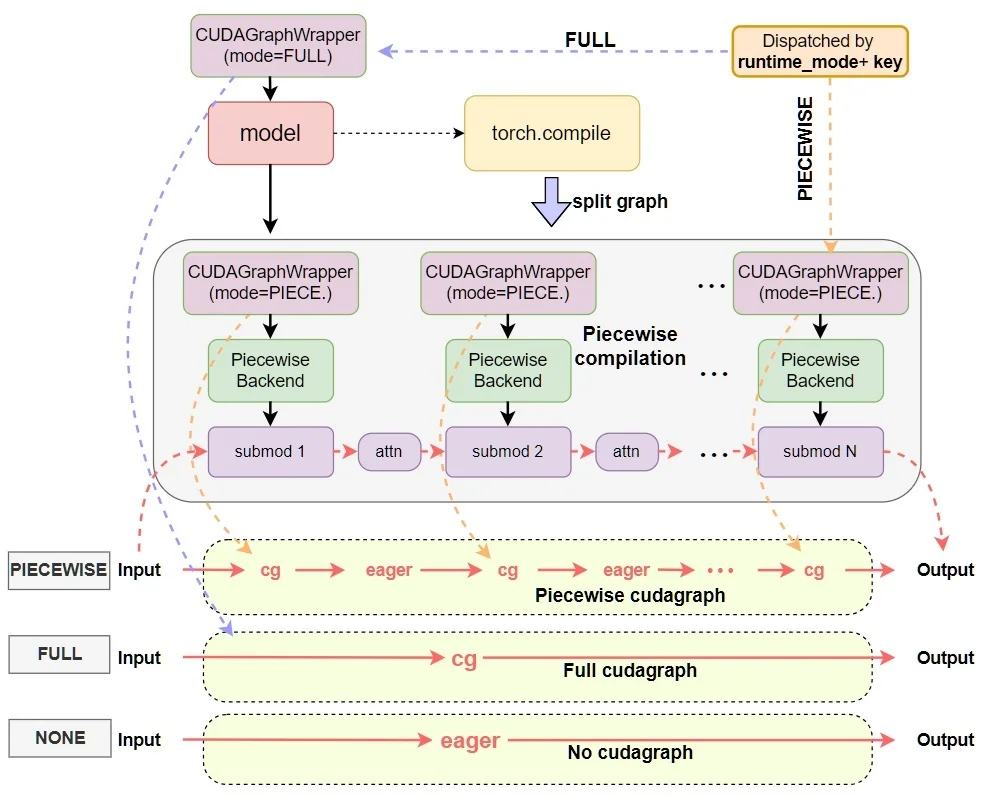
SGLang 的技術創新
SGLang 是由 加州大學柏克萊分校、上海交通大學 和 德州農工大學 多名研究人員於 2024 年 6 月提出的新 LLM 服務架構(論文連結:https://arxiv.org/pdf/2312.07104)。
vLLM 的 PagedAttention 採用分頁管理單一請求的 KV Cache,但沒有跨請求的前綴共享。相比之下,SGLang 提出的 RadixAttention 可以管理 KV Cache 並實現跨請求共享前綴,命中率更高,緩存命中率提升 3-5 倍。SGLang 分離了 prefill 和 decode 後端,支援約束解碼和思維鏈,執行效率更高。
為什麼 Agent 應用需要 SGLang?
近代 LLM 能力大幅提升,可以處理更廣泛的一般任務。例如採用 MoE 架構 的 LLM(包括 DeepSeek 等),可以利用 autonomous agents(自主智能體)建立不同應用,讓 LLM 進行多輪規劃、推理與外部環境互動,通過使用工具、多種輸入模式以及提示技術實現全自動化的工作流程。這標誌著人類與 LLM 互動發生了巨大轉變,從簡單的聊天轉向更複雜的程式化應用,意味著以程式來調度和控制大型語言模型的生成過程。
不少 LLM 支援思維鏈(Chain of Thought),但有時會影響工具調用。LLM 有時側重思維,導致無法輸出正確的 JSON 結構,因而無法執行或呼喚工具。例如 gpt-oss-120b 輸出的 JSON 格式經常出錯,無法被程式精準解析和執行。
推理框架是工具調用的決策大腦,確保模型能合理判斷:是否使用工具、使用哪個工具、如何使用工具。這些因素直接決定了工具調用的可用性、準確性和擴展性,尤其在生產級 AI 應用(如 RAG、智能助手、自動化工作流)中,都需要調用大量工具。因此,未來使用 LLM 必須優先考慮調用工具的效果。
SGLang 在約束解碼和工具調用的優勢
SGLang 在約束解碼(Constrained Decoding)和思維鏈(Chain of Thought, CoT)方面的改進,使其能夠實現可靠的工具調用(Function Call)。例如執行 Claude Code 和 OpenAI Code 時涉及大量工具調用和編碼,vLLM 的表現會出現問題。由於 vLLM 的設計針對密集推理(類似 Llama),面對結構化任務(如 Function Call、執行約束或從內容抽取 JSON)時,可能因為大量推理而無法正確執行工具。
類似 OpenClaw 的應用就大量利用 SGLang 的 RadixAttention 實現更高的緩存命中率,更重要的是在工具調用方面表現更好。約束解碼是工具調用的前提:有了約束解碼,可以強制 LLM 輸出指定的 JSON 格式,利用工具提取目標資訊。
多 GPU 並行處理性能比較
**SGLang 亦支援多 GPU 並行的 tensor parallelism,表現比 vLLM 更佳。**在 Mixtral-8x7B 模型上使用 tensor parallelism(張量並行處理)的測試中,SGLang 的標準化吞吐量明顯優於 vLLM。數值越高越好,這意味著如果使用多於一部的 Ascent GX10 AI Workstation,用戶應該考慮安裝 SGLang。
vLLM vs SGLang:如何選擇?
vLLM 的優勢在於高吞吐量、大量批次處理,以及需要最大穩定性和即時支援新模型的情境。在多用戶、高並發的情況下,vLLM 仍是首選。
SGLang 在速度上通常比 vLLM 快 10-20%(在某些特定基準測試中甚至高達 2-5 倍),這得益於其 RadixAttention 技術,能有效地在多個請求之間緩存鍵值(KV)狀態。
SGLang 在互動性強、聊天密集或「代理式」應用中表現出色,尤其是在需要隨時間累積上下文的場景。在產生結構化 JSON 輸出方面也更快,特別適合支援混合模式的 Linear Attention 和 prefix sharing,在這些情境下 KV Cache 的命中率極高。
SGLang 特別適合部署 Agent 的原因
Agent 的 system prompt 通常較長,而且 function call 重複性高,多輸對話的歷史也會重複,這對於推理的 prefix sharing 非常有利,可以大幅提升輸出 Token 的速度,尤其是在部署多 Agent 工作時。
簡單來說,如果你的 Agent 使用同一個 LLM 工作,所有 Agent 共享 LLM 的權重(因此不影響記憶體耗用)。例如 70B 模型佔用 35GB,但每個 Agent 都有自己的 KV Cache。假設上下文為 256K,每個 Agent 佔用 2.5 GB(FP8 精度),10 個 Agent 就是 25GB。獨立的 Agent KV Cache 可能佔用大部分記憶體。
因此,如果 Spark GB10 Grace Blackwell 需要進行多 Agent 大量批次處理,SGLang 是更好的選擇。在多 Agent 調用時,使用新一代的 Qwen 3.5 可以獲得很好的效果,大大減少記憶體佔用。在 Claude Code 和 Qwen Code 的多輪工具調用和 function call 場景中,SGLang 的優勢更加明顯。如果使用 OpenClaw 的多 Agent 架構,KV Cache 命中率會更高。
在 Spark GB10 上安裝 SGLang
在 Spark GB10 上安裝 SGLang 相當簡單。首先確保系統已安裝 CUDA 12.1 或以上版本,然後通過以下命令完成基本安裝:
pip install "sglang[all]"


